
Deep Learning has revolutionized the domain of Computer Vision. Over the years, research has proved successful to enable computers to mimic human perspective of the real world. This research has widened the scope of using Computer softwares for tasks which were otherwise tedious for humans as a result also reducing human error. A good application of Computer Vision is detecting humans in a video or an image to monitor suspicious activities or study human behavior. In case of Sports Analysis, player movements are traced to study their tactics and strategize for future games.
This Project involved recognizing humans in an image with boundind boxes using a pretrained YOLOv3 model based on Darknet 53 architecture.
Tools Used:
- Python 3
- Apache MXNet
- GluonCV
- Matplotlib
- Jupyter Lab
Object Detection is a subdomain of Computer Vision in which objects present in a frame or image are represented using a rectangle otherwise known as a bounding box. Each of these bounding boxes can be represented using one of the following two formats:
- Pascal-VOC bounding box: (x-top left, y-top left, x-bottom-right, y-bottom-right)
The (x-top-left, y-top-left) together gives the Cartesian coordinates of top-left point of the bounding box assuming the top-left point of the image as the origin (0,0). The (x-bottom-right, y-bottom-right) give the Cartesian coordinates of the bottom-right point of the image with the same assumptions.
- COCO bounding box: (x-top-left, y-top-left, width, height)
The (x-top-left, y-top-left) gives the Cartesian coordinates for top-left point of the bounding box considering the top-left point of the image as the origin (0,0). The width and height of the bounding boxare then given relative to total width and height of the image respectively. The COCO bounding box format is used for YOLO architectures.
Researchers successfully developed three different algorithms for object detection as follows:
- Regions with Convolutional Neural Networks (R-CNN)
- Single Shot Detector (SSD)
- You Look Only Once (YOLO)
Each of these algorithms has its advantages and drawbacks. The Faster R-CNN with Resnet 101 architecture pretrained on COCO dataset performs slower as compared to YOLOv3 with Darknet 53 architecture. However the MAP (Mean Average Precision) score, a metric used to compare Object Detection algorithms; is higher for R-CNN than YOLOv3 for COCO test dataset. This implies that YOLOv3 architecture can process more frames per second with fairly lower accuracy whereas a Faster R-CNN architecture will process less frames per second but with higher accuracy.
This Project involves detecting humans in an image with bounding boxes. An application of this Project is to trace human movement in an environment from one frame to next used in Sports Analysis to study movement of players and determine new tactics to strategize for future games. Since the primary requirement for video analysis is to process higher frames per second (atleast 30), I chose the YOLOv3 with Darknet 53 architecture for this Project.
To implement the architecture, I used the Apache Mxnet API built on top of Pytorch. The
Mxnet API has its own implementation of ndarray similar to numpy ndarray. The Mxnet Gluon
CV library has a sophisticated Model Zoo with most popular Deep Learning architectures.
Having used Tensorflow 1.x,Tensorflow 2.x and Pytorch for Deep Learning Projects, I can
agree that Gluon CV has a more simpler and straightforward API to use pretrained models
than the formers. In this Project, I used the YOLOv3 with Darknet 53 architecture
pretrained on COCO dataset using the syntax below:
model = gluoncv.model_zoo.get_model('yolo3_darknet53_coco, pretrained=True).
- resnet18_v1
- resnet34_v1
- resnet50_v1
- resnet101_v1
- resnet152_v1
- resnet18_v2
- resnet34_v2
- resnet50_v2
- resnet101_v2
- resnet152_v2
- resnest50
- resnest101
- resnest200
- resnest269
- se_resnet18_v1
- se_resnet34_v1
- se_resnet50_v1
- se_resnet101_v1
- se_resnet152_v1
- se_resnet18_v2
- se_resnet34_v2
- se_resnet50_v2
- se_resnet101_v2
- se_resnet152_v2
- vgg11
- vgg13
- vgg16
- vgg19
- vgg11_bn
- vgg13_bn
- vgg16_bn
- vgg19_bn
- alexnet
- densenet121
- densenet161
- densenet169
- densenet201
- squeezenet1.0
- squeezenet1.1
- googlenet
- inceptionv3
- xception
- xception71
- mobilenet1.0
- mobilenet0.75
- mobilenet0.5
- mobilenet0.25
- mobilenetv2_1.0
- mobilenetv2_0.75
- mobilenetv2_0.5
- mobilenetv2_0.25
- mobilenetv3_large
- mobilenetv3_small
- mobile_pose_resnet18_v1b
- mobile_pose_resnet50_v1b
- mobile_pose_mobilenet1.0
- mobile_pose_mobilenetv2_1.0
- mobile_pose_mobilenetv3_large
- mobile_pose_mobilenetv3_small
- ssd_300_vgg16_atrous_voc
- ssd_300_vgg16_atrous_coco
- ssd_300_vgg16_atrous_custom
- ssd_512_vgg16_atrous_voc
- ssd_512_vgg16_atrous_coco
- ssd_512_vgg16_atrous_custom
- ssd_512_resnet18_v1_voc
- ssd_512_resnet18_v1_coco
- ssd_512_resnet50_v1_voc
- ssd_512_resnet50_v1_coco
- ssd_512_resnet50_v1_custom
- ssd_512_resnet101_v2_voc
- ssd_512_resnet152_v2_voc
- ssd_512_mobilenet1.0_voc
- ssd_512_mobilenet1.0_coco
- ssd_512_mobilenet1.0_custom
- ssd_300_mobilenet0.25_voc
- ssd_300_mobilenet0.25_coco
- ssd_300_mobilenet0.25_custom
- faster_rcnn_resnet50_v1b_voc
- mask_rcnn_resnet18_v1b_coco
- faster_rcnn_resnet50_v1b_coco
- faster_rcnn_fpn_resnet50_v1b_coco
- faster_rcnn_fpn_syncbn_resnet50_v1b_coco
- faster_rcnn_fpn_syncbn_resnest50_coco
- faster_rcnn_resnet50_v1b_custom
- faster_rcnn_resnet101_v1d_voc
- faster_rcnn_resnet101_v1d_coco
- faster_rcnn_fpn_resnet101_v1d_coco
- faster_rcnn_fpn_syncbn_resnet101_v1d_coco
- faster_rcnn_fpn_syncbn_resnest101_coco
- faster_rcnn_resnet101_v1d_custom
- faster_rcnn_fpn_syncbn_resnest269_coco
- custom_faster_rcnn_fpn
- mask_rcnn_resnet50_v1b_coco
- mask_rcnn_fpn_resnet50_v1b_coco
- mask_rcnn_resnet101_v1d_coco
- mask_rcnn_fpn_resnet101_v1d_coco
- mask_rcnn_fpn_resnet18_v1b_coco
- mask_rcnn_fpn_syncbn_resnet18_v1b_coco
- mask_rcnn_fpn_syncbn_mobilenet1_0_coco
- custom_mask_rcnn_fpn
- cifar_resnet20_v1
- cifar_resnet56_v1
- cifar_resnet110_v1
- cifar_resnet20_v2
- cifar_resnet56_v2
- cifar_resnet110_v2
- cifar_wideresnet16_10
- cifar_wideresnet28_10
- cifar_wideresnet40_8
- cifar_resnext29_32x4d
- cifar_resnext29_16x64d
- fcn_resnet50_voc
- fcn_resnet101_coco
- fcn_resnet101_voc
- fcn_resnet50_ade
- fcn_resnet101_ade
- psp_resnet101_coco
- psp_resnet101_voc
- psp_resnet50_ade
- psp_resnet101_ade
- psp_resnet101_citys
- deeplab_resnet101_coco
- deeplab_resnet101_voc
- deeplab_resnet152_coco
- deeplab_resnet152_voc
- deeplab_resnet50_ade
- deeplab_resnet101_ade
- deeplab_resnest50_ade
- deeplab_resnest101_ade
- deeplab_resnest200_ade
- deeplab_resnest269_ade
- deeplab_resnet50_citys
- deeplab_resnet101_citys
- deeplab_v3b_plus_wideresnet_citys
- icnet_resnet50_citys
- icnet_resnet50_mhpv1
- resnet18_v1b
- resnet34_v1b
- resnet50_v1b
- resnet50_v1b_gn
- resnet101_v1b_gn
- resnet101_v1b
- resnet152_v1b
- resnet50_v1c
- resnet101_v1c
- resnet152_v1c
- resnet50_v1d
- resnet101_v1d
- resnet152_v1d
- resnet50_v1e
- resnet101_v1e
- resnet152_v1e
- resnet50_v1s
- resnet101_v1s
- resnet152_v1s
- resnext50_32x4d
- resnext101_32x4d
- resnext101_64x4d
- resnext101b_64x4d
- se_resnext50_32x4d
- se_resnext101_32x4d
- se_resnext101_64x4d
- se_resnext101e_64x4d
- senet_154
- senet_154e
- darknet53
- yolo3_darknet53_coco
- yolo3_darknet53_voc
- yolo3_darknet53_custom
- yolo3_mobilenet1.0_coco
- yolo3_mobilenet1.0_voc
- yolo3_mobilenet1.0_custom
- yolo3_mobilenet0.25_coco
- yolo3_mobilenet0.25_voc
- yolo3_mobilenet0.25_custom
- nasnet_4_1056
- nasnet_5_1538
- nasnet_7_1920
- nasnet_6_4032
- simple_pose_resnet18_v1b
- simple_pose_resnet50_v1b
- simple_pose_resnet101_v1b
- simple_pose_resnet152_v1b
- simple_pose_resnet50_v1d
- simple_pose_resnet101_v1d
- simple_pose_resnet152_v1d
- residualattentionnet56
- residualattentionnet92
- residualattentionnet128
- residualattentionnet164
- residualattentionnet200
- residualattentionnet236
- residualattentionnet452
- cifar_residualattentionnet56
- cifar_residualattentionnet92
- cifar_residualattentionnet452
- resnet18_v1b_0.89
- resnet50_v1d_0.86
- resnet50_v1d_0.48
- resnet50_v1d_0.37
- resnet50_v1d_0.11
- resnet101_v1d_0.76
- resnet101_v1d_0.73
- mobilenet1.0_int8
- resnet50_v1_int8
- ssd_300_vgg16_atrous_voc_int8
- ssd_512_mobilenet1.0_voc_int8
- ssd_512_resnet50_v1_voc_int8
- ssd_512_vgg16_atrous_voc_int8
- alpha_pose_resnet101_v1b_coco
- vgg16_ucf101
- vgg16_hmdb51
- vgg16_kinetics400
- vgg16_sthsthv2
- inceptionv1_ucf101
- inceptionv1_hmdb51
- inceptionv1_kinetics400
- inceptionv1_sthsthv2
- inceptionv3_ucf101
- inceptionv3_hmdb51
- inceptionv3_kinetics400
- inceptionv3_sthsthv2
- c3d_kinetics400
- p3d_resnet50_kinetics400
- p3d_resnet101_kinetics400
- r2plus1d_resnet18_kinetics400
- r2plus1d_resnet34_kinetics400
- r2plus1d_resnet50_kinetics400
- r2plus1d_resnet101_kinetics400
- r2plus1d_resnet152_kinetics400
- i3d_resnet50_v1_ucf101
- i3d_resnet50_v1_hmdb51
- i3d_resnet50_v1_kinetics400
- i3d_resnet50_v1_sthsthv2
- i3d_resnet50_v1_custom
- i3d_resnet101_v1_kinetics400
- i3d_inceptionv1_kinetics400
- i3d_inceptionv3_kinetics400
- i3d_nl5_resnet50_v1_kinetics400
- i3d_nl10_resnet50_v1_kinetics400
- i3d_nl5_resnet101_v1_kinetics400
- i3d_nl10_resnet101_v1_kinetics400
- slowfast_4x16_resnet50_kinetics400
- slowfast_4x16_resnet50_custom
- slowfast_8x8_resnet50_kinetics400
- slowfast_4x16_resnet101_kinetics400
- slowfast_8x8_resnet101_kinetics400
- slowfast_16x8_resnet101_kinetics400
- slowfast_16x8_resnet101_50_50_kinetics400
- resnet18_v1b_kinetics400
- resnet34_v1b_kinetics400
- resnet50_v1b_kinetics400
- resnet101_v1b_kinetics400
- resnet152_v1b_kinetics400
- resnet18_v1b_sthsthv2
- resnet34_v1b_sthsthv2
- resnet50_v1b_sthsthv2
- resnet101_v1b_sthsthv2
- resnet152_v1b_sthsthv2
- resnet50_v1b_ucf101
- resnet50_v1b_hmdb51
- resnet50_v1b_custom
- fcn_resnet101_voc_int8
- fcn_resnet101_coco_int8
- psp_resnet101_voc_int8
- psp_resnet101_coco_int8
- deeplab_resnet101_voc_int8
- deeplab_resnet101_coco_int8
- center_net_resnet18_v1b_voc
- center_net_resnet18_v1b_dcnv2_voc
- center_net_resnet18_v1b_coco
- center_net_resnet18_v1b_dcnv2_coco
- center_net_resnet50_v1b_voc
- center_net_resnet50_v1b_dcnv2_voc
- center_net_resnet50_v1b_coco
- center_net_resnet50_v1b_dcnv2_coco
- center_net_resnet101_v1b_voc
- center_net_resnet101_v1b_dcnv2_voc
- center_net_resnet101_v1b_coco
- center_net_resnet101_v1b_dcnv2_coco
- center_net_dla34_voc
- center_net_dla34_dcnv2_voc
- center_net_dla34_coco
- center_net_dla34_dcnv2_coco
- dla34
- simple_pose_resnet18_v1b_int8
- simple_pose_resnet50_v1b_int8
- simple_pose_resnet50_v1d_int8
- simple_pose_resnet101_v1b_int8
- simple_pose_resnet101_v1d_int8
- vgg16_ucf101_int8
- inceptionv3_ucf101_int8
- resnet18_v1b_kinetics400_int8
- resnet50_v1b_kinetics400_int8
- inceptionv3_kinetics400_int8
- hrnet_w18_small_v1_c
- hrnet_w18_small_v2_c
- hrnet_w30_c
- hrnet_w32_c
- hrnet_w40_c
- hrnet_w44_c
- hrnet_w48_c
- hrnet_w18_small_v1_s
- hrnet_w18_small_v2_s
- hrnet_w48_s
- siamrpn_alexnet_v2_otb15
Code Walkthrough
import mxnet as mx
from mxnet.gluon.data.vision import transforms
import gluoncv as gcv
from gluoncv import model_zoo, data, utils
import os
import matplotlib.pyplot as plt
from pathlib import Path
cwd = Path()
pathImages = Path(cwd, 'images')
pathModels = Path(cwd, 'models')
model_name = 'yolo3_darknet53_coco'
model = gcv.model_zoo.get_model(model_name, pretrained=True, root=pathModels)
Helper Functions
# read image as nd array
def load_image(path):
return mx.nd.array(mx.image.imread(path))
# display nd array image
def show_image(array):
plt.imshow(array)
fig = plt.gcf()
fig.set_size_inches(12, 12)
plt.show()
# preprocess image using normalization and resizing to predict objects for yolov3 model
def preprocess_image(array):
return gcv.data.transforms.presets.yolo.transform_test(array)
# detect objects within image using model
def detect(_model, _data):
class_ids, scores, bounding_boxes = _model(_data)
return class_ids, scores, bounding_boxes
# draw and display bounding boxes for detected objects on image
def draw_bbs(unnorm_array, bounding_boxes, scores, class_ids, all_class_names):
ax = utils.viz.plot_bbox(unnorm_array, bounding_boxes, scores, class_ids, class_names=model.classes)
fig = plt.gcf()
fig.set_size_inches(12, 12)
plt.show()
# count number of objects detected in image for an object_label
def count_object(network, class_ids, scores, bounding_boxes, object_label, threshold=0.75):
target_idx = network.classes.index(object_label)
num_objects = 0
for i in range(len(class_ids[0])):
if class_ids[0][i].asscalar() == target_idx and scores[0][i].asscalar() >= threshold:
num_objects += 1
return num_objects
Load and display raw image
image = load_image(Path(pathImages, '02.jpg'))
show_image(image.asnumpy())

Preprocess image
norm_image, unnorm_image = preprocess_image(image)
show_image(unnorm_image)

Detect and draw bounding boxes on objects
# Detect persons
class_ids, scores, bounding_boxes = detect(model, norm_image)
#
draw_bbs(unnorm_array = unnorm_image,
bounding_boxes=bounding_boxes[0],
scores=scores[0],
class_ids=class_ids[0],
all_class_names=model.classes
)

To streamline the process of loading image, preprocessing, detecting inference and
counting the number of bounding boxes in the image, a PersonCounter class is used.
Any raw image requires preprocessing to be used with the model. The shortest dimension
of the image is downsized to 416px and the other dimension is downsized proportionally.
Also, the pixel values of the original image as 8 bit integers (0-255) are scaled to 0-1
and then normalized using mean of 0.485, 0.456, 0.406 and standard
deviation of 0.229, 0.224, 0.225 accross the RGB channels.
The PersonCounter class contains three methods set_threshold, count
and _visualize. The set_threshold method is used to set the minimum confidence
score in order for the detected bounding box to be counted as a prediction.
Since the image is transformed before finding the inference on the model,
the _visualize method comes in handy
to draw predicted bounding boxes on the raw untransformed image.
Finally, the count method is responsible for loading image, preprocessing it,
detecting objects & visualizing them using bounding
boxes, and finally counting the number of humans in the image. The code below shows
the PersonCounter class and its methods.
class PersonCounter():
def __init__(self, threshold):
self._network = gcv.model_zoo.get_model(model_name,
pretrained=True,
root=pathModels
)
self._threshold = threshold
def set_threshold(self, threshold):
self._threshold = threshold
def count(self, filepath, visualize=False):
# Load and Preprocess image
image = load_image(filepath)
if visualize:
show_image(image.asnumpy())
norm_image, unnorm_image = preprocess_image(image)
# Detect persons
class_ids, scores, bounding_boxes = detect(self._network, norm_image)
#
if visualize:
self._visualize(unnorm_image, class_ids, scores, bounding_boxes)
# Count no of persons
num_people = count_object(
network=self._network,
class_ids=class_ids,
scores=scores,
bounding_boxes=bounding_boxes,
object_label="person",
threshold=self._threshold)
if num_people == 1:
print('{} person detected in {} with minimum {} % confidence.'.format(num_people, filepath, self._threshold * 100))
else:
print('{} people detected in {} with minimum {} % confidence.'.format(num_people, filepath, self._threshold * 100))
return num_people
def _visualize(self, unnorm_image, class_ids, scores, bounding_boxes):
draw_bbs(unnorm_array = unnorm_image,
bounding_boxes=bounding_boxes[0],
scores=scores[0],
class_ids=class_ids[0],
all_class_names=self._network.classes
)
counter = PersonCounter(threshold=0.6)
images = ['01.jpeg', '02.jpg', '03.jpg', '04.jpg']
for img in images:
print('Image name', img, sep=":")
counter.count(filepath=Path(pathImages, img), visualize=True)
print('*'*50+'\n\n')
Image name:01.jpeg

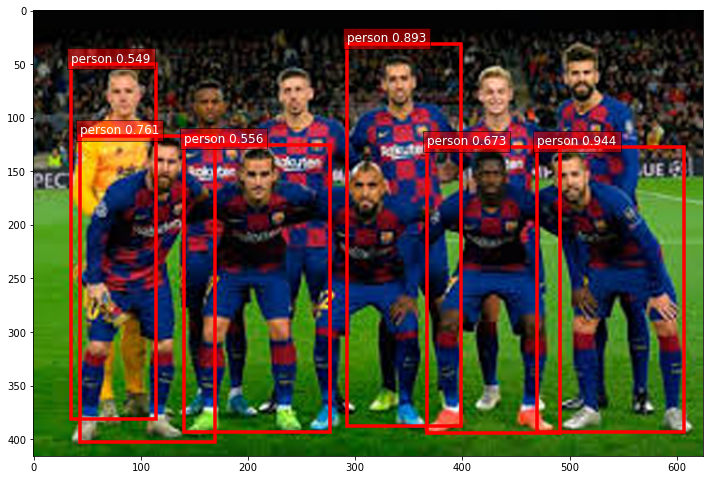
4 people detected in images\01.jpeg with minimum 60.0 % confidence.
**************************************************
Image name:02.jpg


9 people detected in images\02.jpg with minimum 60.0 % confidence.
**************************************************
Image name:03.jpg


13 people detected in images\03.jpg with minimum 60.0 % confidence.
**************************************************
Image name:04.jpg


3 people detected in images\04.jpg with minimum 60.0 % confidence.
**************************************************